11.12学术报告
Scaling Task Synthesis for Large Language Model Reasoning
主要内容是关于任务合成和数据合成
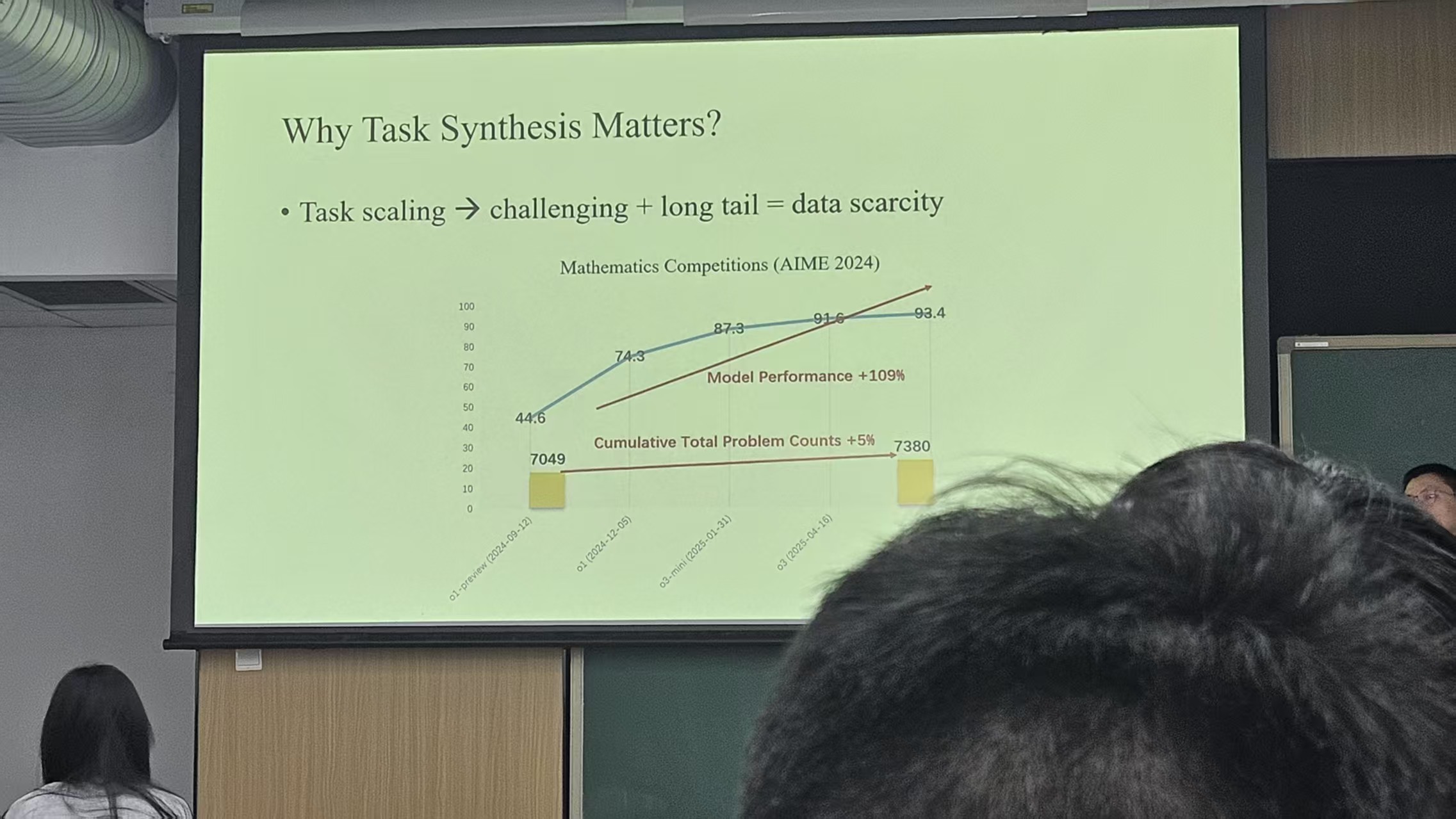
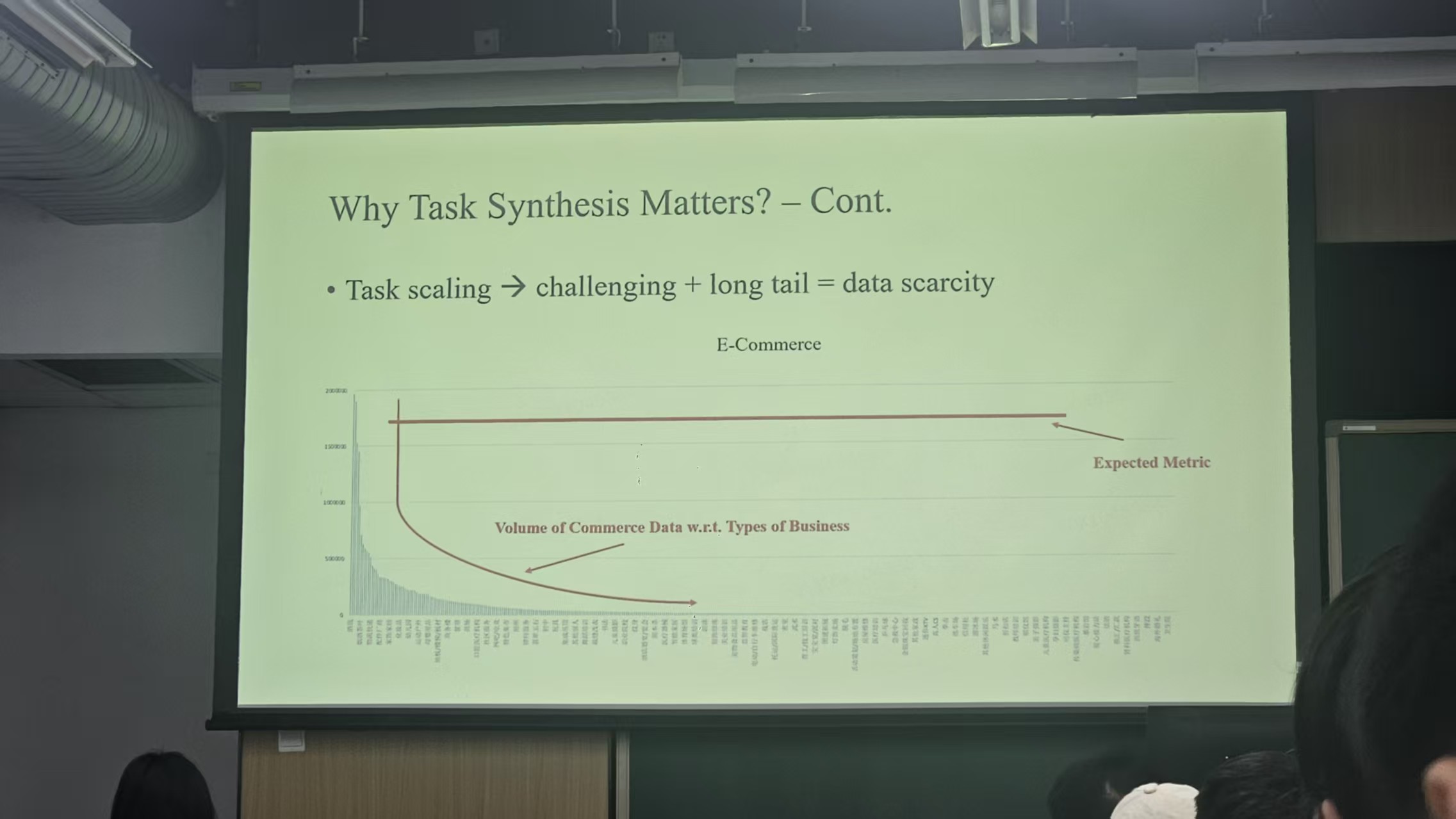
在场景较多,或者说在真实环境下,真正能够用于解决用户问题的数据是稀疏的。比如一个问题有10个可能的解法,其中有2种是正确的,而用户真实需要的其实只有一种解法,因此如何让少数据达到和多数据一样的效果,任务合成是必要的。(这句话可能有点啰嗦,总之就是说任务合成是很重要的,甚至和强化学习一样重要)
他们在 数学题 这个场景下进行分析
- 如何衡量生成问题的难度?
用另一个模型专用于解题:这个模型做的越差,推理过程越长,就证明合成的数据(题目)越难、越复杂
显然,这个评测方法有瑕疵,但他们想不到更好的办法去评测题目难度
- 如何去判断生成的问题的正确性
他是这么解释的(我可能记忆不是很准确,但是大概的意思应该是这样):人类去判断出的题对不对,要先去做了才知道,如果做的过程中发现了矛盾,或者说解不出来,就说明这个题目是错误的。因此对于模型也是如此,生成的题目对不对,要解题模型做了才知道,解题模型做的对不对,那就不一定了。所以这就成了先有蛋还是先有鸡的问题。但是事实上,如果我们生成的问题中有1/3是错误的,有2/3是正确的,其实我们再训一组就能达到很好的效果(指2/3+2/3>1),总之意思就是数据量上去,复杂度上去,模型最后能实现很好的效果就行了,能提高模型任务合成的能力就行。但是如果模型合成100个问题,90个都是重复的,那这个就不是期望的模型达到的效果了。
These slides are part of the presentation


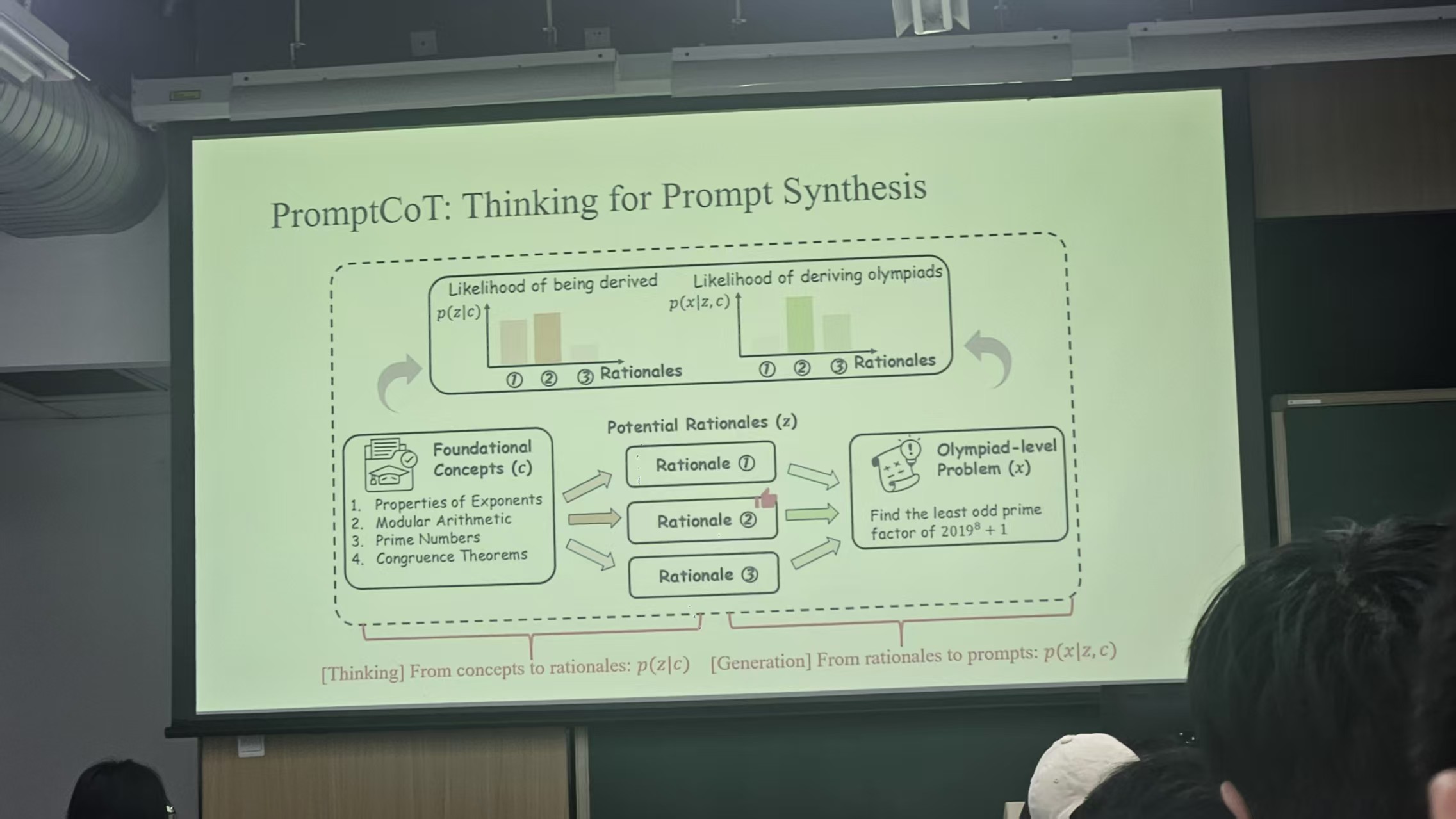
Prompt CoT 主要是问题合成,其中1.0混有人工生成的数据
2.0版本的所有数据都由模型合成




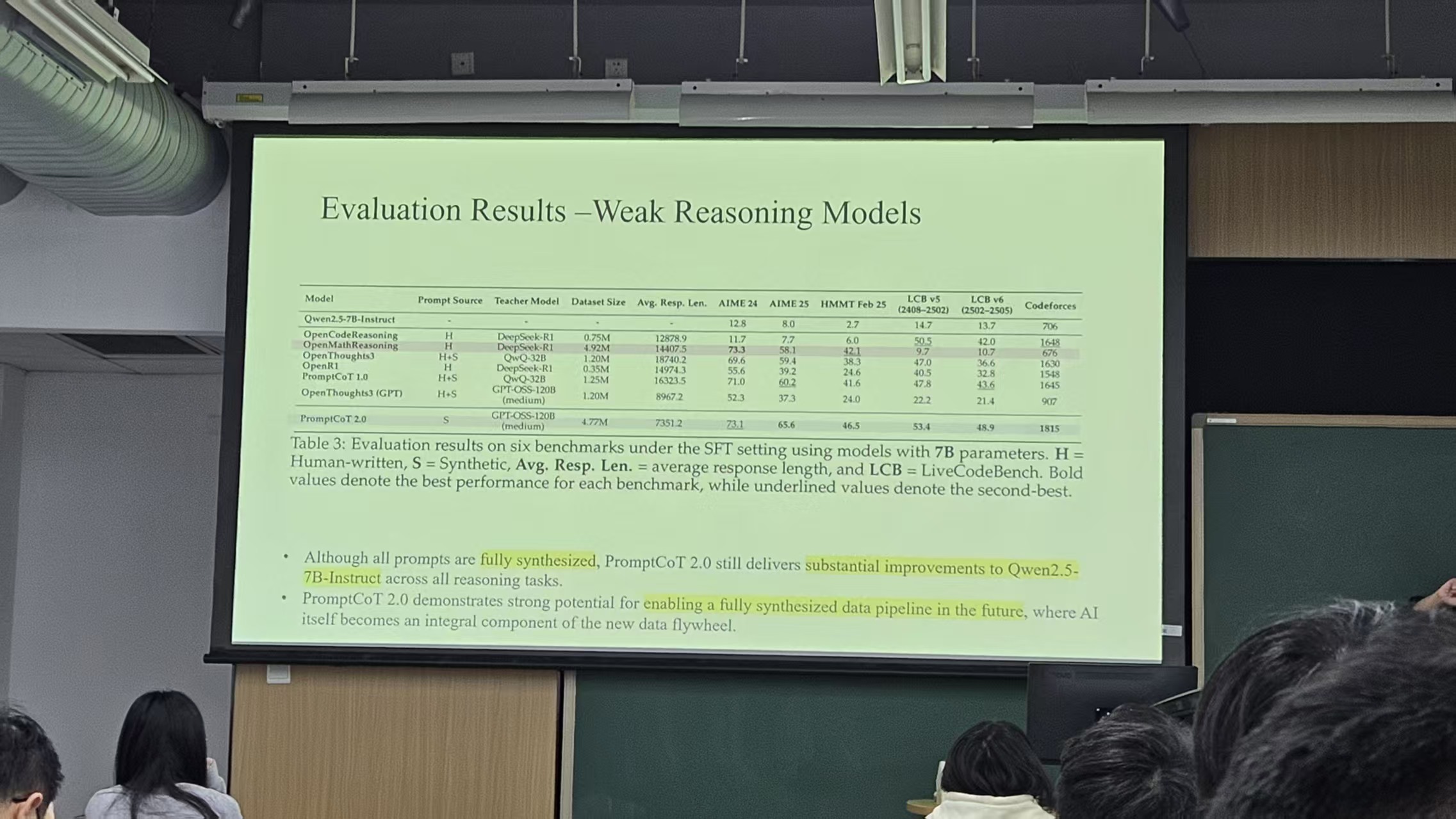

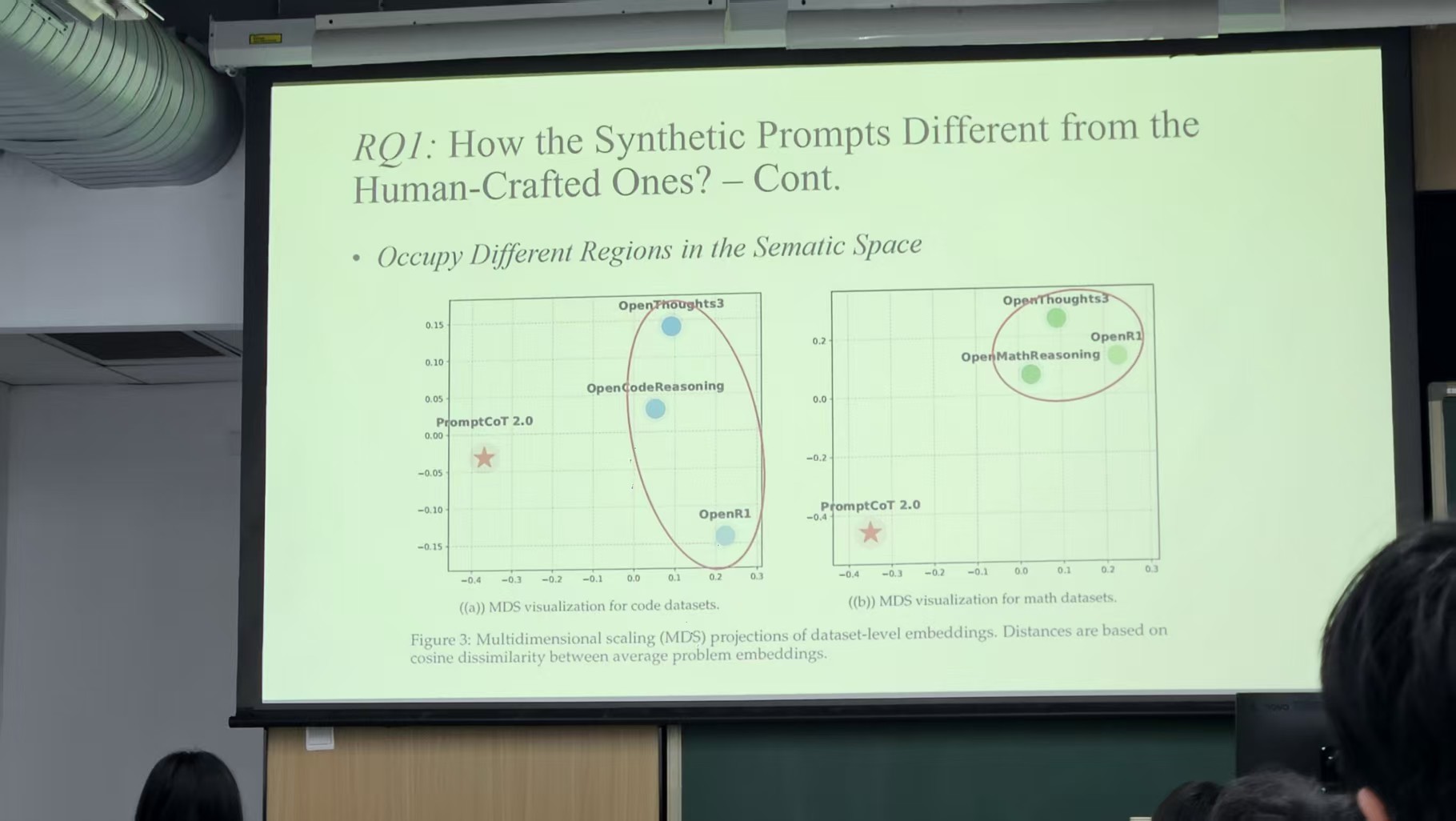
可以发现,虽然提供数据的机构不同,但他们的数据源是比较相近的(这里的数据是人工合成的)

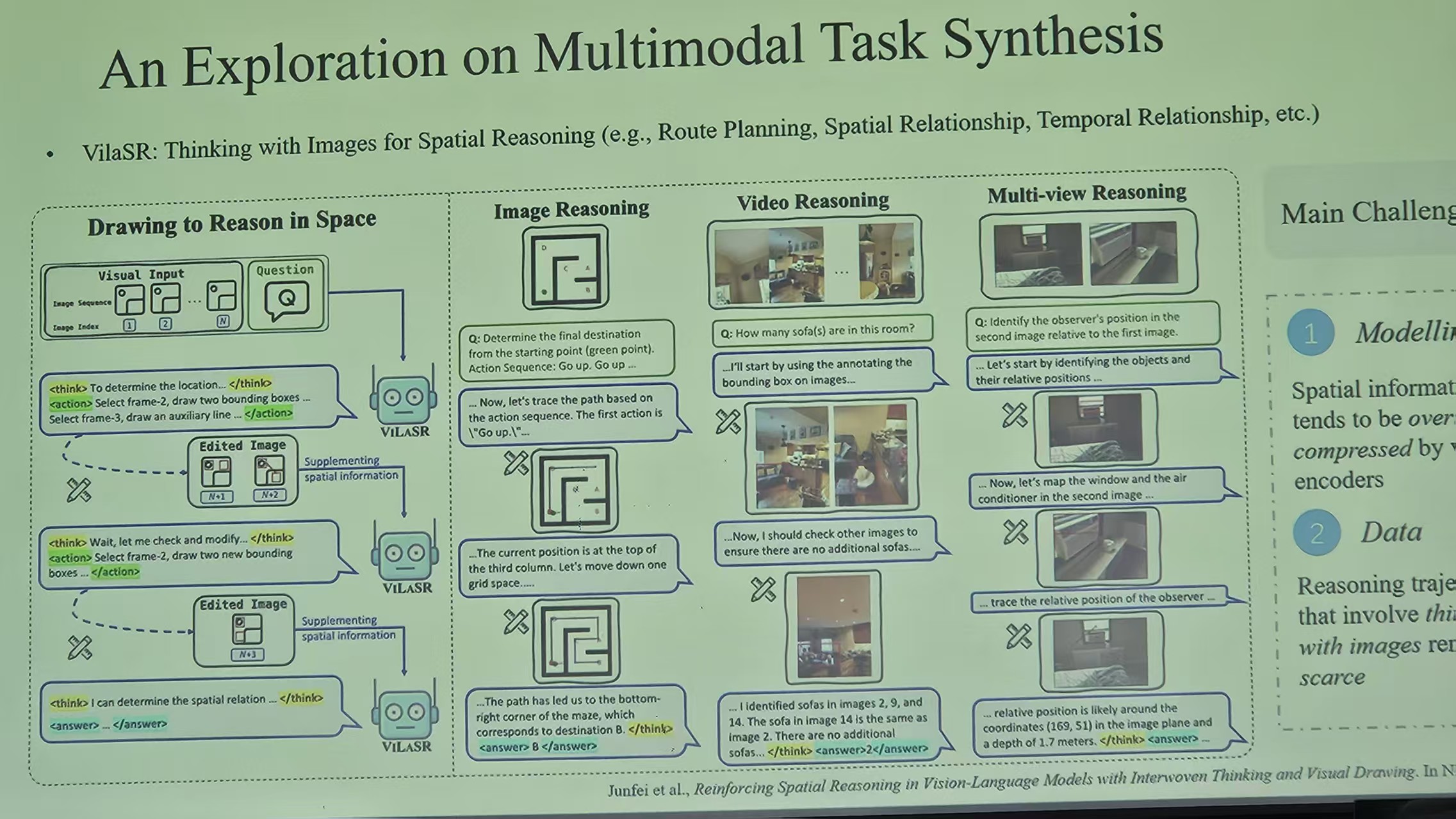
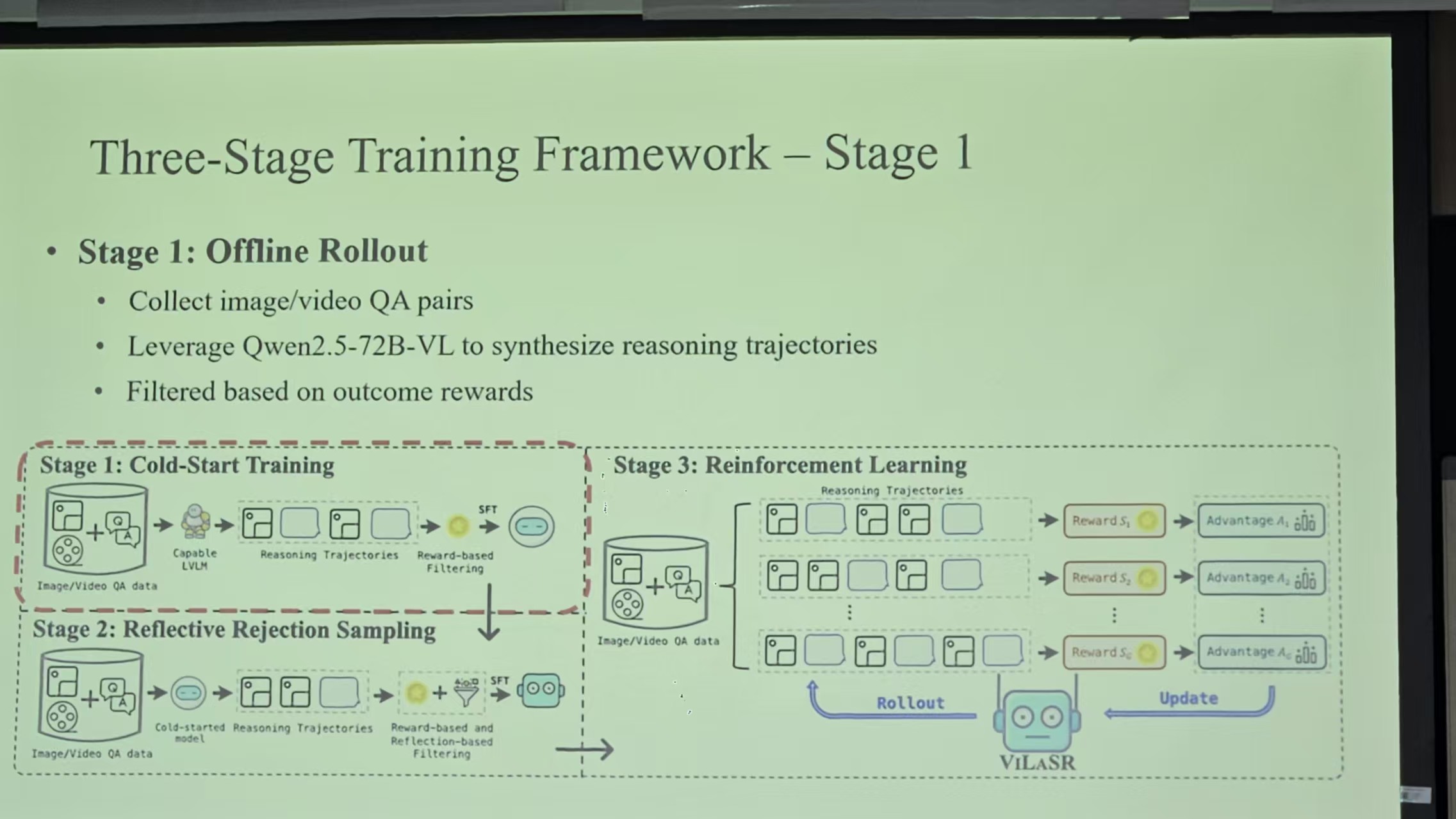
多模态方面的工作